Pimp tes cartes!

Vous est-il déjà arrivé d’être fasciné par l’élégance d’une carte? J’en conviens, pour la majorité d’entre nous (j’en connais qui seraient en désaccord 👀), la visualisation de statistiques classiques sous forme de graphiques est rarement quelque chose d’émouvant. Cependant, en ajoutant un aspect spatial, ça devient généralement beaucoup plus accrocheur, j’oserais même dire excitant!
Le but de cet article, comme son titre le laisse sous-entendre, est de vous donner quelques trucs pour pimper vos cartes interactives créées en pour leur donner une allure professionnelle.
Données utilisées
Les différents exemples qui suivront dans l’article illustrent le revenu total médian des ménages en 2015 pour la division de recensement de Québec. Ces données sont ouvertes et disponibles sur le site de Statistiques Canada. Comme il n’est pas dans la portée d’apprendre à traiter spécifiquement ces données de recensement, j’ai inclus l’ensemble des données requises pour reproduire les exemples de l’article, déjà nettoyées et prêtes à être utilisées. Vous pouvez facilement les télécharger en cliquant ici.
Les fichiers inclus sont :
ada_qc.shp: Limites des aires de diffusions agrégées;da_qc.shp: Limites des aires de diffusions;hydro_qc.shp: Limites hydrographiques;medincome_qc.csvy: Revenu total médian des ménages en 2015.
On charge donc ceux-ci en mémoire. Vous verrez dans le bloc de code ci-dessous qu’on utilisera le package
data.table pour la gestion des données. Les colonnes spatiales seront de classe sfc définie dans le package
sf. Prendre note qu’il y aurait plusieurs autres manières de travailler, comme par exemple utiliser directement la classe
sf pour la gestion des données. Il ne s’agit vraiment que d’une préférence personnelle.
# Charger les packages
library(data.table)
library(sf)
# Lire les couches spatiales
ada_qc <- read_sf("data/ada_qc.shp") %>% setDT()
da_qc <- read_sf("data/da_qc.shp") %>% setDT()
hydro_qc <- read_sf("data/hydro_qc.shp") %>% setDT()
# Lire les données sur le revenu total médian des ménages
medincome_qc <- fread("data/medincome_qc.csvy", yaml = TRUE)On affiche ensuite ce qu’il y a dans les objets ada_qc et medincome_qc.
ada_qc[]
#> ADAUID geometry
#> 1: 24230032 <XY[1]>
#> 2: 24230029 <XY[1]>
#> 3: 24230030 <XY[1]>
#> 4: 24230031 <XY[1]>
#> 5: 24230001 <XY[1]>
#> ---
#> 66: 24230070 <XY[1]>
#> 67: 24230071 <XY[1]>
#> 68: 24230072 <XY[1]>
#> 69: 24230073 <XY[1]>
#> 70: 24230074 <XY[1]>
medincome_qc[]
#> type id med_income
#> 1: ada 24230001 94687
#> 2: ada 24230003 75898
#> 3: ada 24230004 77845
#> 4: ada 24230005 79467
#> 5: ada 24230007 57568
#> ---
#> 1268: da 24250312 131190
#> 1269: da 24250313 130816
#> 1270: da 24250314 108800
#> 1271: da 24250315 84890
#> 1272: da 24250316 99226Afin d’être en mesure de créer une carte contenant les informations de revenu moyen, on doit combiner l’information spatiale et tabulaire dans la même table.
Pour ce faire, on utilise la syntaxe de fusion par référence de data.table. On affiche ensuite le résultat.
# Faire la fusion
ada_qc[medincome_qc[type == "ada"], med_income := med_income, on = c(ADAUID = "id")]
da_qc[medincome_qc[type == "da"], med_income := med_income, on = c(DAUID = "id")]
# Afficher le résultat pour ada_qc
ada_qc[]
#> ADAUID geometry med_income
#> 1: 24230032 <XY[1]> 40749
#> 2: 24230029 <XY[1]> 64922
#> 3: 24230030 <XY[1]> 66641
#> 4: 24230031 <XY[1]> 47381
#> 5: 24230001 <XY[1]> 94687
#> ---
#> 66: 24230070 <XY[1]> 50667
#> 67: 24230071 <XY[1]> 95604
#> 68: 24230072 <XY[1]> 106445
#> 69: 24230073 <XY[1]> 53902
#> 70: 24230074 <XY[1]> 64329On a maintenant tout ce dont on a de besoin pour créer une carte illustrant le revenu total médian des ménages en 2015 pour l’ensemble des aires de diffusion agrégées de la division de recensement de Québec 🥳.
Carte de base
Avant d’apprendre à pimper une carte interactive, on commence par en produire une de base avec le package leaflet.
Je vous invite à consulter la documentation du package pour comprendre l’effet des différentes fonctions et de leurs arguments respectifs.
Le seul point sur lequel j’insisterai est la valeur de l’argument data de la fonction addPolygons(). Vous remarquerez que j’ai transformé le data.table
en objet de classe sf (à l’aide de la fonction st_as_sf()) et que je l’ai reprojeté en longitude/latitude (à l’aide de la fonction st_transform()). Ces
deux étapes sont nécessaires pour faciliter l’intégration avec leaflet.
# Charger le package
library(leaflet)
# Créer une carte interactive de base
leaflet(
width = "100%"
) %>%
addTiles() %>%
addPolygons(
data = ada_qc %>% st_as_sf() %>% st_transform(4326L),
weight = 1L,
color = gray(0.3),
opacity = 1,
fillColor = ~colorNumeric(
palette = "Greens",
domain = range(med_income)
)(med_income),
fillOpacity = 0.5
)Cette carte est efficace pour illustrer nos données, mais pourrait facilement être améliorée à l’aide de quelques astuces simples.

Suggestions d’améliorations
Chacune des améliorations listées dans cette section peut être incorporée à une carte interactive de manière indépendante. En fonction du contexte, certaines astuces seront plus bénéfiques que d’autres, il n’y a pas de recette universelle. On les présente donc successivement et on créera ensuite une carte pimpée les incluant toutes dans la section suivante.
Fond de carte
Dans l’exemple simple, on a utilisé les tuiles de fond de carte par défaut de la fonction addTiles(). Ces tuiles sont très complètes et présentent
une panoplie d’informations. Souvent, c’est tout simplement trop 😖. Je vous invite donc à choisir judicieusement vos fonds de carte pour
mettre l’accent sur ce que vous cherchez vraiment à illustrer. Vous pouvez facilement voir les tuiles préprogrammées avec
leaflet ici. Pour ma part, mes préférées sont
Positron et DarkMatter du fournisseur CartoDB.
Un autre point qu’on peut facilement améliorer avec les tuiles de fond de carte consiste à diviser en deux couches distinctes la couche de base et les étiquettes. Si vous n’aviez pas remarqué, allez jeter un coup d’oeil à la carte de la section précédente. Comme les polygones sont affichés par-dessus les tuiles, il devient difficile de lire les étiquettes. Le problème devient encore pire lorsqu’on augmente l’opacité des polygones. La solution pour contourner ce problème est d’afficher la couche de base en arrière-plan, les étiquettes au premier plan et les polygones en sandwich entre les deux.

Pour ce faire, on va créer trois panneaux de carte avec la fonction addMapPane(). L’argument zIndex permet de spécifier le niveau de profondeur du panneau.
Plus l’argument zIndex est élevé, plus la couche sera vers l’avant.
Domaine de valeurs
Jusqu’à maintenant, on ne s’est pas posé de questions par rapport à l’échelle de couleurs qui est utilisée sur la carte. J’imagine que vous avez déduit qu’on
a spécifié qu’on voulait une échelle de différents verts avec l’argument palette qui prend la valeur "Greens" 🤑. Les plus
observateurs auront aussi remarqué qu’on a spécifié l’étendue de cette échelle à l’aide de l’argument domain. Comme la fonction range() retourne les
valeurs minimale et maximale de son argument, l’échelle qu’on a défini est linéaire entre le minimum
(35 523 $) et le maximum
(144 981 $) des revenus médians par aire de diffusion agrégée.
Évidemment, cette définition d’échelle n’est pas toujours optimale. Ci-dessous, on affiche la distribution des revenus médians par aire de diffusion agrégée à
l’aide du package ggplot2. On attache aussi le package scales (déjà chargé avec
ggplot2, mais non attaché) pour la gestion des différents formats à afficher.
# Charger les packages
library(ggplot2)
library(scales)
# Créer l'histogramme
ggplot(
data = ada_qc,
mapping = aes(
x = med_income
)
) +
geom_bar() +
scale_x_binned(
labels = label_number(),
) +
labs(
x = "Revenu total médian des ménages en 2015 ($)",
y = "Nombre d'aires de diffusion agrégées",
caption = "Division de recensement de Québec"
) +
theme_minimal()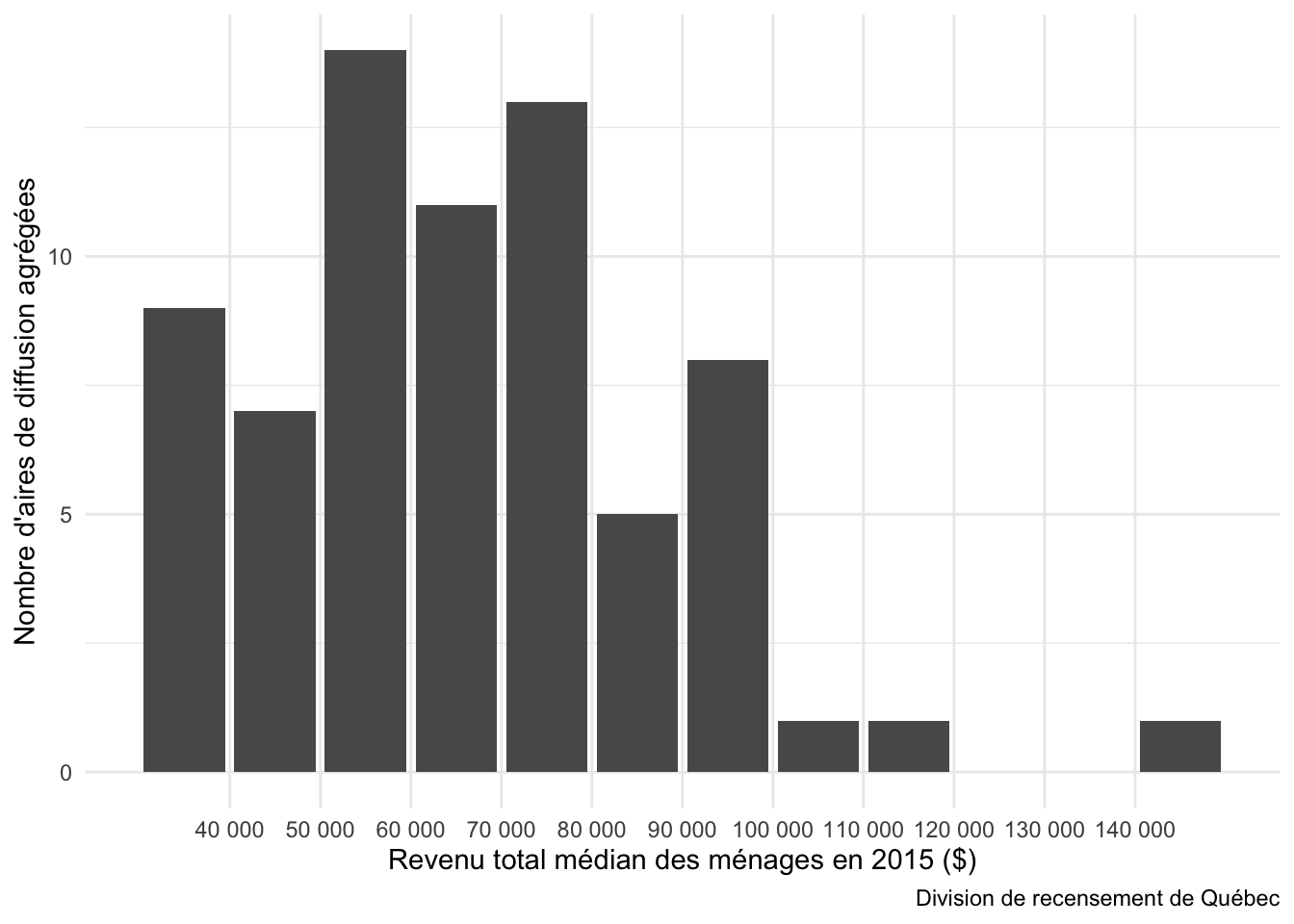
En analysant cet histogramme, on voit qu’une échelle linéaire entre 30 000 $ et 100 000 $ donnerait probablement un meilleur résultat. Les valeurs à
l’extérieur de cet intervalle seront tronquées à l’aide de la fonction squish().
# On définit le domaine de valeur sélectionné
med_income_domain <- c(30L, 100L) * 1000LInteractions avec le curseur
Une autre amélioration possible est de personnaliser l’interaction à l’aide du curseur. Plusieurs actions sont possibles, mais on se contentera de montrer
l’effet de mettre en surbrillance et d’afficher une étiquette lorsqu’on touche à un polygone. On utilisera l’argument highlightOptions pour la surbrillance
et les arguments label et labelOptions pour les étiquettes.
Pour donner un effet de surbrillance intéressant, on va augmenter l’opacité du remplissage et foncir et épaissir les contours du polygone. Pour les étiquettes, on utilisera de simples chaînes de caractères pour l’exemple. Pour avoir un contrôle total, on aurait aussi plutôt pu fournir directement le code html à afficher au passage de la souris. J’invite les lecteurs un peu plus expérimentés (ou un peu plus geeks 🤓) à l’essayer!
Découpage hydrographique
Cette suggestion d’amélioration est parfois intéressante, mais souvent moins importante que celles présentées jusqu’à maintenant. Tel que suggéré par le sous-titre, on va découper le réseau hydrographique de notre couche de polygones.
On commence par créer un objet spatial contenant une union de tous les cours d’eau présents dans la région d’intérêt à l’aide de la fonction st_union(). On
découpe ensuite les polygones à l’aide de la fonction st_difference().
# Créer l'objet hydro_qc_union
hydro_qc_union <- hydro_qc[, st_union(geometry)]
# Découper les polygones
ada_qc[, geometry_nohydro := st_difference(geometry, hydro_qc_union)]
da_qc[, geometry_nohydro := st_difference(geometry, hydro_qc_union)]Granularité dynamique
La dernière suggestion d’amélioration proposée est celle d’une granularité dynamique de la couche de polygones déterminée en fonction du niveau de zoom. Les polygones illustrés représenteront la granularité suivante :
- Niveau de zoom entre 10 et 12 : aires de diffusion agrégées;
- Niveau de zoom entre 13 et 15 : aires de diffusion.
Afin d’éviter de répéter la fonction addPolygons() avec ses nombreux arguments, on créera une fonction addMedIncomePolygons() qui définira les arguments
constants d’une couche de polygones à l’autre.
# Définir la fonction addMedIncomePolygons()
addMedIncomePolygons <- function(map, data, group) {
addPolygons(
map = map,
data = data %>% st_as_sf(sf_column_name = "geometry_nohydro") %>% st_transform(4326L),
group = group,
weight = 1L,
color = gray(0.3),
opacity = 1,
fillColor = ~colorNumeric(
palette = "Greens",
domain = med_income_domain
)(squish(med_income, med_income_domain)),
fillOpacity = 0.5,
highlightOptions = highlightOptions(
weight = 3,
color = "black",
fillOpacity = 0.7,
bringToFront = TRUE
),
label = ~dollar(
x = med_income,
prefix = NULL,
suffix = " $",
big.mark = " "
),
labelOptions = labelOptions(
direction = "top",
offset = c(0, -5)
),
options = pathOptions(
pane = "med_income"
)
)
}On met tout ça ensemble
Si on applique toutes les suggestions proposées dans la section précédente, on obtient la carte ci-dessous.
# Créer une carte pimpée
leaflet(
width = "100%",
options = leafletOptions(
minZoom = 10L,
maxZoom = 15L
)
) %>%
addMapPane(
name = "background",
zIndex = 100L
) %>%
addMapPane(
name = "med_income",
zIndex = 400L
) %>%
addMapPane(
name = "labels",
zIndex = 500L
) %>%
addProviderTiles(
provider = providers$CartoDB.PositronNoLabels,
options = pathOptions(
pane = "background"
)
) %>%
addProviderTiles(
provider = providers$CartoDB.PositronOnlyLabels,
options = pathOptions(
pane = "labels"
)
) %>%
addMedIncomePolygons(ada_qc, "ada") %>%
addMedIncomePolygons(da_qc, "da") %>%
groupOptions("ada", 10:12) %>%
groupOptions("da", 13:15)Beaucoup mieux, n’est-ce pas?

Conclusion
Ça fait plusieurs mois que j’avais en tête l’idée de créer un blogue portant sur différents sujets reliés à la science des données. Je ne prenais pas le temps de mettre ce plan à exécution, mais voilà qui est finalement fait 😃.
Le sujet de mon premier article était une formalité puisque ça faisait déjà quelques fois que des collègues me demandaient de leur expliquer comment faire de belles cartes en . J’espère que celui-ci vous a plu et, surtout, qu’il vous sera utile lorsque vous créerez vos prochaines cartes.
Si vous avez des suggestions pour de futurs articles, des sujets que vous aimeriez approfondir davantage, n’hésitez pas à m’en faire part 🤗!
J.P. Le Cavalier
Scientifique de données / Actuaire
Je me considère un modèle hybride entre un actuaire et un scientifique de données. J’adore prendre le temps de bien faire les choses.